LLM推理01-lookahead decoding性能测试
术语:
- LADE:lookahead decoding缩写。
简介
LADA方法介绍:https://lmsys.org/blog/2023-11-21-lookahead-decoding/
LADE GitHub仓库:https://github.com/hao-ai-lab/LookaheadDecoding
测试流程
下载并安装:
git clone https://github.com/hao-ai-lab/LookaheadDecoding.git |
执行官方demo:
# 不使用LADE |
提示:如果遇到报错:
We couldn't connect to '[https://huggingface.co](https://huggingface.co/)' to load this file,须检查代理问题,确认代理可访问huggingface。
测试结果
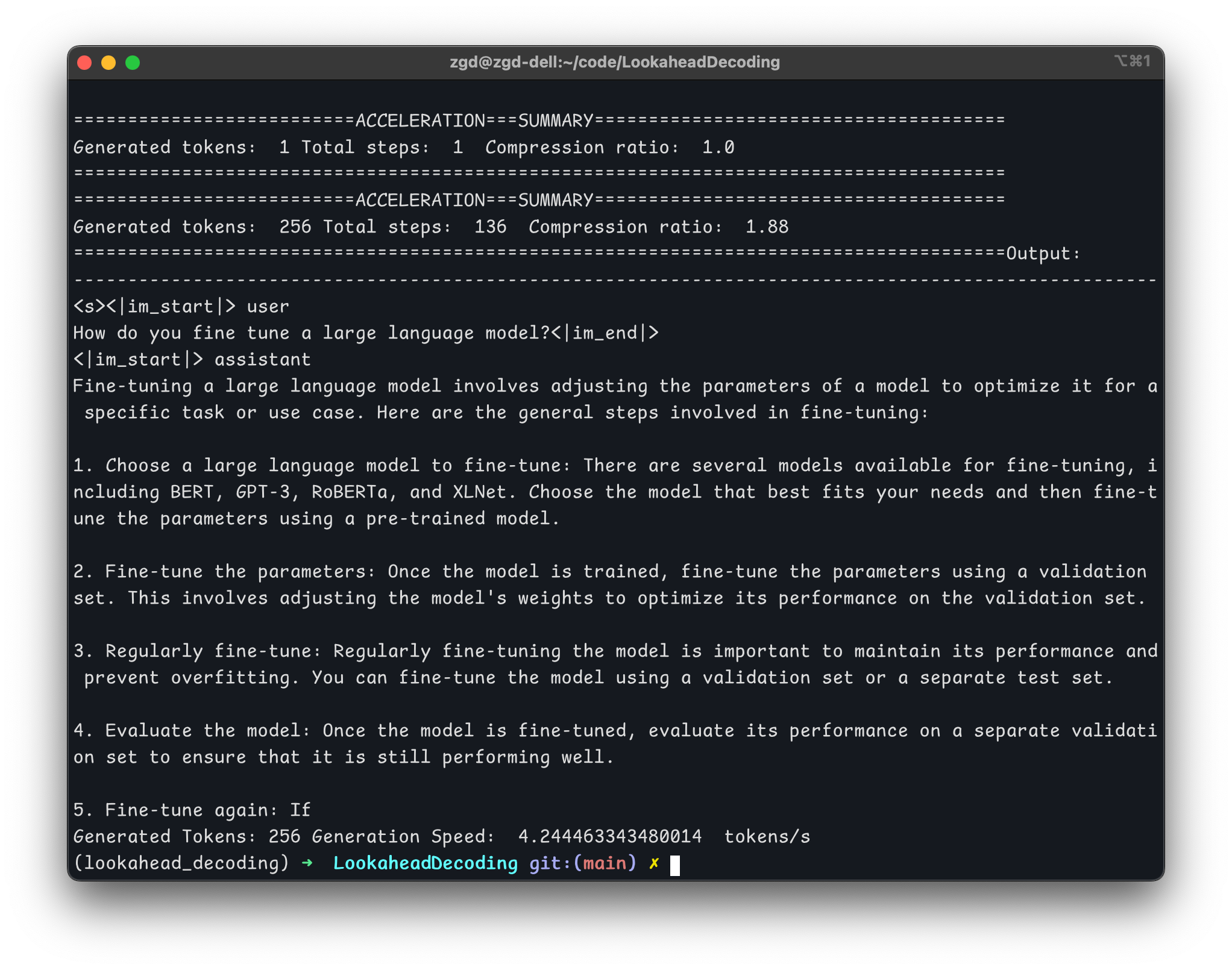
1、本地RTX-1050Ti with 4G RAM
- 不使用LADE:14.5 tokens/s

- 使用LADE:4.2 tokens/s
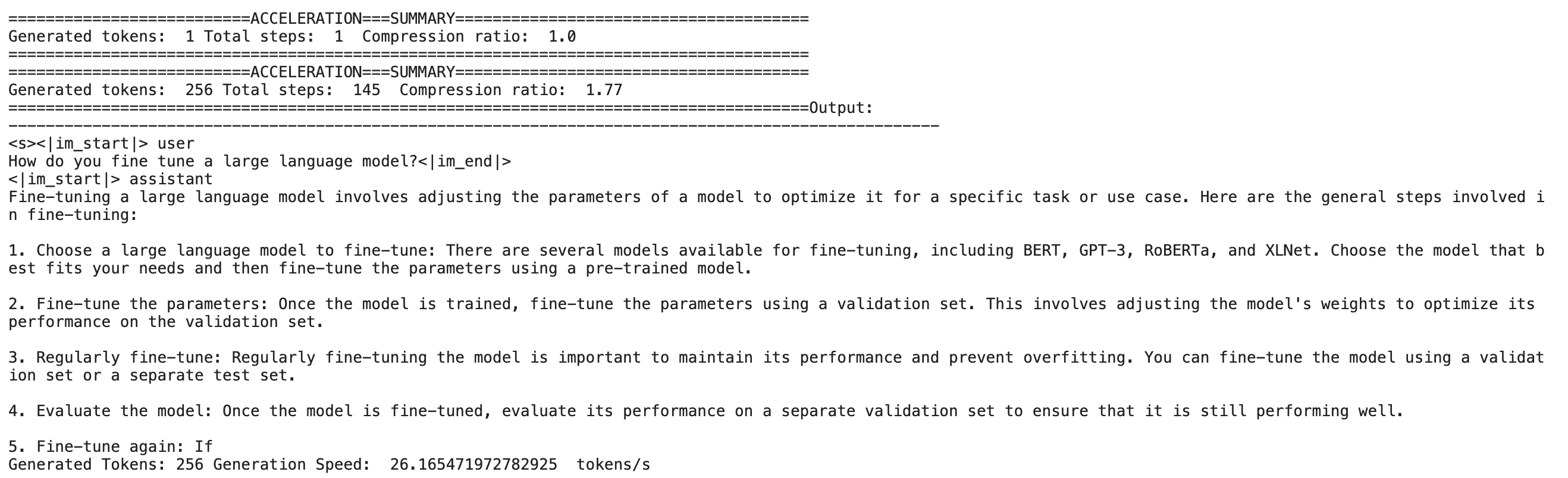
2、Nvidia P100 with 16G RAM
- 不使用LADE:40.7 tokens/s

- 使用LADE:26.2 tokens/s
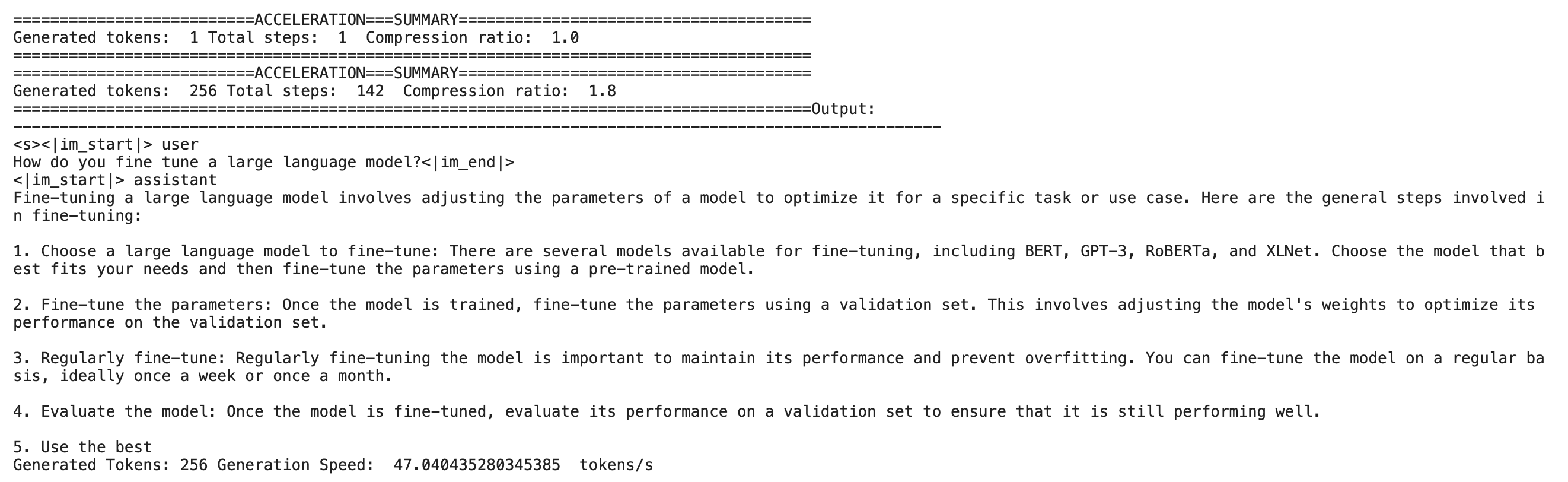
3、Nvidia T4x2 with 16GB RAM
- 不使用LADE:37.2 tokens/s

- 使用LADE:47.0 tokens/s
性能数据汇总:
| 不使用LADE推理速度(tokens/s) | 使用LADE推理速度(tokens/s) | 性能提升比例(lade/origin - 1.0) | |
|---|---|---|---|
| RTX 1050Ti | 14.5 | 4.2 | -0.71 |
| P100 | 40.7 | 26.2 | -0.36 |
| T4 x 2 | 37.2 | 47.0 | 0.26 |
分析与小结
从官方Tiny-llama示例的实测结果看:
(1)LADE方法在三种硬件上,只有T4x2上有26%的提示,其它两种均有显著劣化。
(2)在RTX 1050Ti和P100上,输出结果的最后一行生成文本,使用LADE和不使用保持一致,但T4x2上,输出结果最后一行不一致。
官方给的数据基于llama2-7b-chat,考虑进一步用相同模型测试,对比官方数据结论。
不过有意思的是:官方给的默认示例,居然是存在性能劣化的,是不是说明这种这种方法的普适性有限。